
ChEMBL 35 is out
The year ends with an update to ChEMBL. This release contains 2.5 million compounds and 1.7 million assays including over 15K drugs or molecules in development.
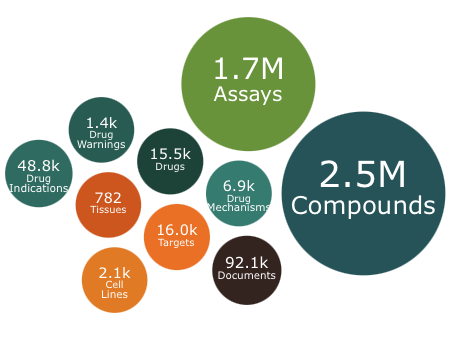
You can download the dataset in various formats https://chembl.gitbook.io/chembl-interface-documentation/downloads.
Full details of the update are on the ChEMBL blog. https://chembl.blogspot.com/2024/12/heres-nice-christmas-gift-chembl-35-is.html.
Seasons Greetings
As many of you know I don't send Christmas cards, instead I give the monies I would have spent to MS Research. Have a great time and a successful New Year,

Comparison of protein structure prediction algorithms
The majority of drug targets are proteins and knowledge of the 3D structure of the protein can be very helpful for structure based design. Whilst the PDB contains 227,933 structures there are still a number of structures that lack structural information. In 2018 Deepmind released AlphaFold an artificial Intelligence program design to predict protein 3D structure from the amino-acid sequence DOI. Since then there have a series of updates that have included the ability to handle small molecules, co-factors, nucleic acids, protein complexes etc. AlphaFold has been used in collaboration with the EBI to create AlphaFold DB which provides open access to over 200 million protein structures, covering the human proteome and the proteomes of 47 other key organisms important in research and global health. A recent addition is Foldseek a protein structural search program that allows users to search the AlphaFold Database.

David Baker, Demis Hassabis and John Jumper were awarded the 2024 Nobel Prize for Chemistry. One half of the prize has been awarded to David Baker “for computational protein design” and the other half jointly to Demis Hassabis and John M. Jumper “for protein structure prediction.”
Whilst AphaFold gets much of the publicity, it has served to spawn a number of related programs, comparison of the different options is difficult especially when looking at the various licensing options. Fortunately, Brian Naughton has posted a very useful summary. http://blog.booleanbiotech.com/alphafold3-boltz-chai1.html.
CSD, ChEMBL, PDBe now interlinked
Three critical databases for drug discovery are now interlinked. The Cambridge Structural Database (CSD) a curated repository of small molecule crystal structures, ChEMBL a manually curated database of bioactive molecules with their associated biological data and PDBe a founding member of the Worldwide Protein Data Bank (wwPDB) which collects, organises and disseminates data on biological macromolecular structures, are now interlinked.
The BioChemGraph (BCG) project tackles the challenge of linking diverse data in biology by creating a resource that integrates data from the PDBe, ChEMBL, and the CSD. This has been achieved by mappings UniProt Accession ID and compound InChIKey, linkingmore than 17,000 experimentally determined protein-ligand complexes from the PDB to about 39,000 ChEMBL bioactivity records. By providing this link it is possible to not only identify binding affinity for the selected target but also much more information about the small molecule ligand, such as off-target activities, calculated physicochemical properties and also any ADME/T data that might be available. All data can be downloaded as a tsv as shown below.

ChEMBL and PDBe have collaborated to set up an automatic pipeline for generating these data. As a result, the data will be updated weekly, in sync with the PDBe release every Wednesday at 00.00 UTC.
InChis have also been used to interconnect with Cambridge Structural Database using UniChem, 235,000 CSD identifiers have been linked corresponding entries in UniChem, a “universal translator” for chemistry using InChIs to connect chemical structures and their identifiers across various databases. UniChem enables researchers to seamlessly access information about a specific molecule across a wide variety of data sources. There are currently 41 data sources (https://www.ebi.ac.uk/unichem/sources).
AlphaProteo generates novel proteins
Protein protein interactions are always a challenge to optimise and it looks like the latest offering from Google DeepMind may be of significant help.
Protein binders that can bind tightly to a target protein are hard to design. Traditional methods are time intensive, requiring multiple rounds of extensive lab work. After the binders are created, they undergo additional experimental rounds to optimize binding affinity, so they bind tightly enough to be usefu
AlphaProteo generates novel proteins that bind to other proteins. Given the structure of a target molecule and a set of preferred binding locations on that molecule, AlphaProteo generates a candidate protein that binds to the target at those locations.
Whilst code is not available, note
If you’re a biologist, whose research could benefit from target-specific protein binding, and you’d like to register interest in being a trusted tester for AlphaProteo, please reach out to us on alphaproteo@google.com.
Privileged Structures
The term "privileged structures" was first coined by Ben Evans DOI: 10.1021/jm00120a002 who recognised the potential of certain regularly occurring structural motifs as templates for derivatization to discovery novel ligands for binding to proteins. In this seminal paper they identified a benzodiazepine and substituted indole as key structures in their work to yield CCK antagonists.
Two very popular privileged structures are N-benzyl piperidine and N-benzyl piperazine. They offer a variety of different interactions (pi-stacking, hydrophobic, electrostatic) with a relatively well defined 3D structure.

A recent publication gives a very nice summary of their use in drug discovery DOI.
Abstract The N-benzyl piperidine (N-BP) structural motif is commonly employed in drug discovery due to its structural flexibility and three-dimensional nature. Medicinal chemists frequently utilize the N-BP motif as a versatile tool to fine-tune both efficacy and physicochemical properties in drug development. It provides crucial cation-π interactions with the target protein and also serves as a platform for optimizing stereochemical aspects of potency and toxicity. This motif is found in numerous approved drugs and clinical/preclinical candidates. This review focuses on the applications of the N-BP motif in drug discovery campaigns, emphasizing its role in imparting medicinally relevant properties. We provide an overview of approved drugs, the clinical and preclinical pipeline, and discuss its utility for specific therapeutic targets and indications, along with potential challenges.
Drug-Induced Liver injury prediction
Many compounds can cause liver injury, after oral administration the first major organ exposed is the liver. The LiverTox is a database of information on the diagnosis, cause, frequency, patterns, and management of liver injury attributable to prescription and nonprescription medications, herbals and dietary supplements.
Checking for the potential to cause liver injury is an important part of the drug discovery process and there are a number of in vitro and in vivo assays that can be used.
High dose studies in safety species are undertaken to identify potential toxicities and to determine safety margins, Clinically, the most relevant reactions include liver necrosis, hepatitis, cholestasis, vascular changes and steatosis. A drug can cause liver toxicity via multiple mechanisms, it can be the result of a direct action of the parent compound or indirectly through reactive metabolites. The drug or its metabolites may cause liver toxicity after specific receptor binding, or reactive metabolites can react with hepatic macromolecules, all leading to direct cytotoxicity. In addition, Immune-mediated idiosyncratic drug reaction has been responsible for numerous serious hepatotoxic events in humans
It would be useful to be able to predict ahead of synthesis whether a molecule was likely to cause liver injury and that is the function of DILIpredictor DOI. Using data form several thousand molecules and a variety of different assays (both in vitro and in vivo) and different species the authors have developed a predictive model. The attraction of this approach is in addition to giving an early flag of potential DILI it also highlights potential species differences and can give an insight into the mechanism.
DILIPredictor required only chemical structures as input for prediction and is publicly available at https://broad.io/DILIPredictor for use via web interface (please don't submit confidential molecules) and with all code available for download from GitHub
https://github.com/srijitseal/DILI_Predictor
I installed like this since it currently does not run with the latest version of python
conda create -n DILIpred python=3.10
conda activate DILIpred
pip install DILIpred
It can then beinstalled as follows.
conda create -n DILIpred python=3.10
conda activate DILIpred
pip install DILIpred
It can then be usef as follows
(DILIpred) chrisswain@Mac-Studio ~ % dilipred -smiles "C[C@@H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C"
If you use DILIPred in your work, please cite: Improved Detection of Drug-Induced Liver Injury by Integrating Predicted In Vivo and In Vitro Data Srijit Seal, Dominic Williams, Layla Hosseini-Gerami, Manas Mahale, Anne E. Carpenter, Ola Spjuth, and Andreas Bender doi: https://doi.org/10.1021/acs.chemrestox.4c00015
100%███████████████████████████████████████████████████████████████ 1/1 [00:01<00:00, 1.14s/it] 2024-07-12 08:29:44.777 | CRITICAL | dilipred.main:predict:458 - The compound is predicted DILI-Positive
The detailed output is contained in a file created.
source,assaytype,description,value,pred,SHAP contribution to Toxicity,SHAP,smiles,smilesr DILI,DILIstFDA,This is the predicted FDA DILIst label,0.8187885151383966,1,N/A,N/A,C[C@@H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C= C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O)c2ccc(F)cc2)C3C)n1 Diverse DILI C,Heterogenous Data ,"Transient liver function abnormalities, adverse hepatic effects",0.7393781727510759,True,Positive,0.003926801602711443,C[C@@H] 1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O )c2ccc(F)cc2)C3C)n1 BESP,Mechanisms of Liver Toxicity,BESP Bile Salt Export Pump Inhibition,0.5655727513227511,True,Positive,0.0003070244326849143,C[C@@H ]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(= O)c2ccc(F)cc2)C3C)n1 Mitotox,Mechanisms of Liver Toxicity,Mitotox ,0.10973983865879627,False,Positive,0.0006130947805277731,C[C@@H]1C2=NN= C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O)c2ccc( F)cc2)C3C)n1 Reactive Metabolite,Mechanisms of Liver Toxicity,Reactive Metabolite Formation,0.19967540492325553,False,Negative,-0.001048102741727997,C[C@@ H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C( =O)c2ccc(F)cc2)C3C)n1 Human hepatotoxicity,Human hepatotoxicity,"Human hepatotoxicity, hepatobiallry",0.7196576912119554,True,Positive,0.007802364907899422,C[C @@H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN( C(=O)c2ccc(F)cc2)C3C)n1 Animal hepatotoxicity A,Animal hepatotoxicity,"Rat, chronic oral administration, Hepatic histopathologic effects, ToxRefDB",0.5867747455286331,True,Positive,0.0030731971130978854,C[C@@H] 1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O )c2ccc(F)cc2)C3C)n1 Animal hepatotoxicity B,Animal hepatotoxicity,"Hepatocellular hypertrophy, rats, ORAD, HESS",0.6646590439473917,True,Positive,0.0013360236463188587,C[C@@H]1C2= NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1 Preclinical hepatotoxicity,Animal hepatotoxicity,"Preclinical hepatotoxicity data from PharmaPendium, Leadscopre, and internal repository with 14- to 28-day rat study data",0.8576928962241468,True,Positive,0.011692057666492625,C[C@@H]1C2= NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1 Diverse DILI A,Heterogenous Data ,Large-scale and diverse ddrug induced liver injury dataset,0.6324274304660036,True,Positive,0.003398315762493277,C[C@@H]1C2 =NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1 source,assaytype,description,value,pred,SHAP contribution to Toxicity,SHAP,smiles,smilesr DILI,DILIstFDA,This is the predicted FDA DILIst label,0.8187885151383966,1,N/A,N/A,C[C@@H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C= C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O)c2ccc(F)cc2)C3C)n1 Diverse DILI C,Heterogenous Data ,"Transient liver function abnormalities, adverse hepatic effects",0.7393781727510759,True,Positive,0.003926801602711443,C[C@@H] 1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O )c2ccc(F)cc2)C3C)n1 BESP,Mechanisms of Liver Toxicity,BESP Bile Salt Export Pump Inhibition,0.5655727513227511,True,Positive,0.0003070244326849143,C[C@@H ]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(= O)c2ccc(F)cc2)C3C)n1 Mitotox,Mechanisms of Liver Toxicity,Mitotox ,0.10973983865879627,False,Positive,0.0006130947805277731,C[C@@H]1C2=NN= C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O)c2ccc( F)cc2)C3C)n1 Reactive Metabolite,Mechanisms of Liver Toxicity,Reactive Metabolite Formation,0.19967540492325553,False,Negative,-0.001048102741727997,C[C@@ H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C( =O)c2ccc(F)cc2)C3C)n1 Human hepatotoxicity,Human hepatotoxicity,"Human hepatotoxicity, hepatobiallry",0.7196576912119554,True,Positive,0.007802364907899422,C[C @@H]1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN( C(=O)c2ccc(F)cc2)C3C)n1 Animal hepatotoxicity A,Animal hepatotoxicity,"Rat, chronic oral administration, Hepatic histopathologic effects, ToxRefDB",0.5867747455286331,True,Positive,0.0030731971130978854,C[C@@H] 1C2=NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O )c2ccc(F)cc2)C3C)n1 Animal hepatotoxicity B,Animal hepatotoxicity,"Hepatocellular hypertrophy, rats, ORAD, HESS",0.6646590439473917,True,Positive,0.0013360236463188587,C[C@@H]1C2= NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1 Preclinical hepatotoxicity,Animal hepatotoxicity,"Preclinical hepatotoxicity data from PharmaPendium, Leadscopre, and internal repository with 14- to 28-day rat study data",0.8576928962241468,True,Positive,0.011692057666492625,C[C@@H]1C2= NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1 Diverse DILI A,Heterogenous Data ,Large-scale and diverse ddrug induced liver injury dataset,0.6324274304660036,True,Positive,0.003398315762493277,C[C@@H]1C2 =NN=C(N2CCN1C(=O)C3=CC=C(C=C3)F)C4=NC(=NS4)C,Cc1nsc(-c2nnc3n2CCN(C(=O) c2ccc(F)cc2)C3C)n1
Overall a useful tool to have to hand.
CCDC: Curated Data Set of Protein Structures
Fantastic news from the Cambridge Crystallographic Data Centre (CCDC), a curated data set of protein structures from the Protein Data Bank (PDB) with predicted hydrogen positions is now available for download. The dataset is taken from the Protein Data Bank (PDB) and has the positions of hydrogens accurately computed, this provides a comprehensive snapshot of protein cavities in the PDB, identifying potential binding sites for small molecules with accurately predicted hydrogen positions for all components.
The news article is here https://www.ccdc.cam.ac.uk/discover/blog/accelerating-drug-discovery-with-the-ccdc-aws-and-intel/.
This large subset of the protein data bank which has be processed using the CCDC's protonation workflow so that reasonable proton positions have been modelled can be downloaded here.
https://www.ccdc.cam.ac.uk/support-and-resources/downloads/.
LLM for Drug Discovery
Whilst general large language models have hit the headlines in recent years, there is a school of thought that smaller domain specific models may actually more useful, in particular in areas like chemistry https://pubs.rsc.org/en/content/articlelanding/2023/dd/d2dd00087c and https://arxiv.org/abs/2402.09391.
A recent preprint describes Tx-LLM a large language model (LLM) for drug discovery https://arxiv.org/pdf/2406.06316. This work from Google Research and Google DeepMind details Tx-LLM, a LLM specifically designed to enhance drug discovery.
Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable. However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities. Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities (small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22. Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining. We observe evidence of positive transfer between tasks with diverse drug types (e.g., tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance. We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
The model was trained using 709 drug discovery datasets comprising 66 tasks formatted for instruction tuning from Therapeutics instruction Tuning (TxT) https://tdcommons.ai collection for tasks across the drug discovery spectrum. These tasks include:
- Evaluating drug efficacy and safety.
- Predicting molecular targets.
- Assessing the ease of manufacturing drugs.
MRC grant for collaboration
Biomedical research often requires collaborations between scientists with different skills so I'm always delighted to highlight grants that help foster collaboration.
This opportunity is intended to support new partnerships between diverse groups of researchers within the remit of Medical Research Council (MRC).
The grant will allow you to:
Establish new, high-value collaborative activities or capabilities
Add value to high-quality scientific programmes that are already supported by grants from MRC and other funders
Funding is available for between one and five years
More details here https://www.ukri.org/opportunity/responsive-mode-partnership/?utmmedium=email&utmsource=govdelivery.
EMBL-EBI User Survey 2024
I suspect many of the readers of this site have used some of EMBL-EBI resources and tools are some time.
EMBL’s European Bioinformatics Institute maintains the world’s most comprehensive range of freely available and up-to-date molecular data resources.
https://www.ebi.ac.uk/services/data-resources-and-tools.
These of course include the Alphafold database. ChEMBL, PDB in Europe and much. Much more.
In order to support continued funding they do regular user surveys, and the latest is now online.
https://www.surveymonkey.com/r/HJKYKTT
It takes around 15 mins to complete so please take a tea break and fill it in.
Small molecule High Throughput Screen using AstraZeneca facilities
This is a really interesting opportunity. With the demise of the European Lead Factory access to a large, high quality screening deck is very limited.
The MRC now have a unique funding opportunity, a chance to screen against the AstraZeneca screening deck. https://www.ukri.org/opportunity/develop-new-approaches-to-small-molecule-medicine/?utmmedium=email&utmsource=govdelivery.
Funding priority in this round will be given to applications related to fibrosis or extracellular matrix targets.
Two funding opportunities a year with new thematic focus each round. Future areas will include:
- autoimmunity
- pain
- motor neuron disease
- mental health
- dementias (including Parkinson’s and Huntington’s)
- women’s health (including related to metabolic disorders)
Often the challenge for small groups is optimisation of the assay to make it suitable for HTS, so it is great this is also to be funded and AZ will provide technical advice
What will funded, costs related to the staff and consumable costs incurred at AstraZencea for the optimisation and execution of the High Throughput Screen (HTS). These include:
- £20,000 (100% FEC Exceptions) – Optimisation and establishment of an HTS
- £150,000 (100% FEC Exceptions) – Execution of the HTS
- cost of travel, accommodation and subsistence for a host institution researcher to work at AstraZeneca in Cambridge for three months (80% FEC)
- costs for elements of the screening cascade that cannot be undertaken at AstraZeneca and must be undertaken at the host organisation (80% FEC)
- minimal %FTE for the project lead (80% FEC)
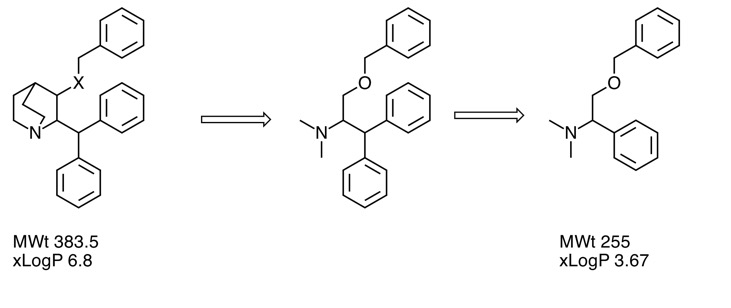
Deconstruction of a screening hit
One strategy to investigate screening hits is to simplify the structure to identify the minimum pharmacophore . Whilst lower in affinity the result will have lower molecular weight and LogP. Indeed the molecule may now occupy "fragment space". When I presented this at the recent Fragments meeting a member of the audience coined the phrase "Deconstruction of a screening hit" and several people used the phrase subsequently so perhaps it will used in the future.
Details are here Deconstruction of a screening hit.
Artificial intelligence, engineering biology and quantum technologies: Funding Opportunity
Apply for funding for the application of artificial intelligence (AI), engineering biology, and quantum technologies in biomedical research and development.
You must be based at a UK research organisation eligible for MRC funding.
You can get funding through any grants from MRC responsive mode or translation funding opportunities. You should apply through the existing funding opportunity that is most relevant to your science area and career stage.
We will usually fund up to 80% of your project’s full economic cost.
This highlight notice will be open from 1 April 2024 to 31 March 2025. Applications submitted in this window will be considered for this highlight opportunity. For individual application closing dates refer to the relevant MRC funding opportunity.
9th Fragment-based Drug Discovery Meeting slides
I'm just back from the 9th Fragment-based Drug Discovery Meeting https://www.rscbmcs.org/events/fragments24/ another fabulous meeting and always great to hear about the multitude of ways that Fragments are impacting drug discovery, from target identification, hit discovery to lead optimisation. A number of people asked if the slides from my talk would be available.
Hopefully this link will be accessible to everyone.
http://cambridgemedchemconsulting.com/news/files/FragHitsMar2024.pdf.
9th Fragment-based Drug Discovery Meeting
I'll be heading over to the 9th Fragment-based Drug Discovery Meeting https://www.rscbmcs.org/events/fragments24/ later today. This event is one of the high points in the Drug Discovery calendar. I'm sure there will be plenty to add to the Fragment-Based Screening section on the Drug Discovery Resources Website.
The aim of the 9th RSC-BMCS Fragment-based Drug Discovery meeting will be to continue the focus on case studies in Fragment-based Drug Discovery that have delivered compounds to late stage medicinal chemistry, preclinical or clinical programmes. The Fragment series was started in 2007 and continues with this theme in having over three-quarters of the presentations focused on case studies. This will be complemented by technology progress in high concentration, NMR, SPR and X-ray screening.
BMCS Hot Topics Meetings
The next meeting is Hot Topics: Covalent Drug Discovery 2024, this online event is on Thursday 16th May, 2024 (afternoon).

To register for the meeting, click here To download the first announcement poster, click here
RSC Pharmaceutics has just published its first articles
Pharmaceutics plays a critical role in drug discovery however since it is often regarded as a development process it is not always given the prominence in basic research that it deserves. The pharmaceutical properties of a drug are absolutely critical in the success of a drug discovery project so I'm delighted to see a new open-access RSC journal on the topic
RSC Pharmaceutics has just published its first articles, https://pubs.rsc.org/en/journals/journalissues/pm#!recentarticles&adv.
BBSRC follow-on fund
Grant funding is a great way of starting of work on novel targets, getting funding to continue the work can be more of an issue. This why I'm delighted to read about the BBSRC follow-on fund to help bridge the gap.
FoF applications must draw substantially on current or prior BBSRC funding. You must be based at a UK research organisation eligible for BBSRC funding.
FoF awards aim to take ideas through to a stage where the route to practical application is clear.
The full economic cost (FEC) of your project can be up to £800,000. BBSRC will fund 80% of the FEC. FoF awards support defined programmes of work for up to two years.
Drug design data sets for testing computational tools
One of the challenges when building novel tools to aid drug discovery is identifying high quality datasets that can be used to test new tools. This is why the D3R datasets are so valuable https://drugdesigndata.org.
These datasets are available from BindingDB and include a variety of important protein targets.

The targets include CathepsinS, BACE1, ABL1) and JAK2.
